PyMTL基础入门
第01章 简介
我们将在接下来的部分使用 PyMTL3 硬件建模框架进行功能级建模、验证以及模拟器的使用。可以选择 PyMTL3 或 Verilog 进行寄存器传输级建模,但即便使用 Verilog,也需完成本教程,因为课程中部分内容仍需使用 PyMTL3。需要注意的是,PyMTL3 是 PyMTL2 的改进版本,虽然二者在 API 上的差异不大,但 PyMTL3 在具体实现上有显著更新,因此需留意这些变化。
本教程聚焦于 PyMTL3 框架的基本知识,包括开发、测试与评估方法,以及课程中使用的代码规范。涉及的开源工具包括:用于测试驱动开发的 pytest 框架,将 Verilog 转为 C++ 的 Verilator,以及用于查看波形的 GTKWave。PyMTL3 框架本身为开源项目,可在 GitHub 上访问 ,我们可以浏览其源码以深入了解框架的实现。
这里提供一个Fedora的建议安装流程(其他发行版类似)。
首先安装依赖项:
1 | sudo dnf install python3 python3-pip python3-venv |
推荐使用Conda创建一个虚拟环境,以便更好地管理依赖关系:
1 | wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh |
运行下载的安装脚本,并按照提示安装:
1 | bash Miniconda3-latest-Linux-x86_64.sh |
完成安装后,初始化 Conda,以便在终端中可以直接使用 conda 命令:
1 | source ~/miniconda3/bin/activate |
在 Conda 安装完成并配置后,您可以创建一个新的环境,用于安装和运行 PyMTL3。使用以下命令创建名为 pymtl3_env 的环境,同时指定 Python 版本:
1 | conda create -n pymtl3_env python=3.8 |
创建环境后,使用以下命令激活 pymtl3_env 环境:
1 | conda activate pymtl3_env |
安装PyMTL3:
1 | pip install pymtl3 |
如果您还需要 Verilator(例如进行 RTL 级仿真),可以从 Fedora 的包管理器中安装:
1 | sudo dnf install verilator |
第02章 PyMTL3 的功能级、周期级和寄存器传输级建模
计算机架构师可以在不同抽象级别上对系统进行建模,包括功能级(Functional-Level, FL)、周期级(Cycle-Level, CL)和寄存器传输级(Register-Transfer-Level, RTL)。每个建模级别都有其独特的优缺点,因此有效的设计通常需要综合利用这些不同的建模级别。未来将通过示例展示如何从 FL 到 CL 再到 RTL 逐步优化设计,尽管在实验作业中主要集中于 FL 和 RTL 建模。
2.1 FL、CL 和 RTL 建模比较
- 功能级 (FL):实现硬件功能而不关注时序。FL 模型适用于探索算法、快速仿真目标硬件和创建黄金模型来验证 CL 和 RTL 模型。这种模型构建简单,但与目标硬件的准确性最低。FL可以看作是算法模拟器,用来快速验证算法或目标硬件的功能是否正确。因为 FL 模型不考虑硬件的时序,因此仿真速度快,构建也相对简单,但它不能精确地代表硬件的实际行为。它通常用于编写“黄金模型”,即参考模型,用来验证其他更精确模型的正确性。
- 周期级 (CL):捕捉硬件目标的近似周期行为,通过在功能行为上增加时序模型来追踪硬件性能,适用于在不同微架构参数下快速探索设计空间。CL 模型在准确性、性能和灵活性之间取得平衡。
- 寄存器传输级 (RTL):提供周期、资源和位级精确的硬件表示,主要用于特定硬件实现的验证和综合。RTL 模型是最为详细的建模方式,适用于驱动 EDA 工具流以估算面积、能耗和时序,但构建较为复杂。
在本教程中,FL、CL 和 RTL 模型都使用基于端口的接口、并发模块和结构化组合的方式。此外,PyMTL3 支持高级多态接口连接,允许不同级别的接口通过自动插入适配器进行直接连接。这种基于端口和多态的方式支持 PyMTL3 的混合级别建模,即可以将 FL、CL 和 RTL 模型组合成一个统一的系统模型。
2.2 可综合与非可综合 RTL 建模
由于 PyMTL3 嵌入在 Python 中(Python 是一种通用编程语言),可以非常容易地编写无法模拟实际硬件的 PyMTL3 代码,而这对于构建 FL 模型、测试框架、断言和行跟踪等功能是必需的。因此,学生在建模时必须谨慎选择自己编写的是可综合的 RTL 模型还是非可综合代码,时刻明确自己在模拟什么样的硬件以及如何模拟。
学生的设计任务几乎完全使用可综合的 PyMTL3 RTL 模型。可以在 update_ff、update 和 update_once 并发模块之外的 Python 代码(即展开代码)中使用任何 Python 代码,因为展开代码用于生成硬件而不是实际建模硬件。在并发模块中可适量包含非可综合代码用于调试、断言或行跟踪,但应通过注释标记这些非可综合代码,以便自动化工具在综合设计前将其移除。
下面包含了一个表格,列出了哪些 Python 结构在可综合的 PyMTL3 并发模块中允许使用、有限制地允许使用以及显式禁止使用的结构。与 ECE 4750 不同,这些规则仅作为建议。我们可以使用 PyMTL3 可翻译成 Verilog 且 Synopsys Design Compiler 可综合的任何内容。如果发现更高级的语法可以简化设计且可被综合,亦可采用该语法。


第03章 PyMTL3基础:数据类型和操作符
从本章开始,我们将从基本内容开始,写一些非常基础的代码来介绍PyMTL3的基础数据类型和操作符。我们通过
1 | from pymtl3 import * |
在Python的开头来导入PyMTL3框架。
3.1 Bits数据类型
在硬件建模框架 PyMTL3 中,Bits 类用于表示固定位宽的值。与许多硬件描述语言 (HDL) 支持四态值(0, 1, X, Z,其中 X 表示未知值,Z 表示高阻抗值)不同,PyMTL3 的 Bits 仅支持二态值(0 和 1)。虽然这种设计可以加速仿真并避免 X 值带来的问题,但也增加了描述一些硬件结构的复杂度。此外,在仅支持二态值的环境下处理复位逻辑可能会有一定挑战,但可以通过已知的技术加以解决。
3.1.1 创建与操作 Bits 对象
以下示例展示了如何在 Python 中实例化和操作 Bits 对象:
- BitsN 构造函数用于创建固定位宽的 Bits 对象。
Bits16(37)表示创建一个 16 位宽的 Bits 对象,并赋初值为 37。 - 在 PyMTL3 中,位宽在 1 至 255 位之间的常用 Bits 类型已经定义。也可以通过
mk_bits(N)动态创建更宽的 Bits 类型。
例如:
1 | a = Bits16(37) # 创建 16 位宽、初值为 37 的 Bits 对象 |
3.1.2 常量、负数与进制支持
- 常量创建:可以通过 bN 语法创建常量,如
b16(37)。
请注意:这里的BitsN都是2进制的位宽,而非N进制的位宽
1 | b16(37) |
- 进制表示:Bits 支持二进制和十六进制表示,如
Bits8(0b10101100)和Bits32(0xabcd0123)。其中:- 二进制(Binary) - 0b 前缀
1 | Bits8( 0b10101100 ) |
- 八进制(Octal) - 0o 前缀
- 十进制(Decimal) - 无前缀
- 十六进制(Hexadecimal) - 0x 前缀
1 | Bits32(0xabcd0123) |
- 负值:Bits 对象可存储负数,采用二进制补码表示,例如
Bits8(-1)将存储为0xff。 - 动态范围检查:当赋值超出位宽允许的范围时,Bits 构造函数将抛出异常。例如,
Bits8(260)将会报错,因为 260 无法用 8 位表示。可以通过以下方式实现:
1 | Bits260 |
- 截断初值:可以通过
trunc_int=True参数来截断过大的初值值,如Bits8(0xdeadbeef, trunc_int=True)将返回Bits8(0xef)。
3.1.3 获取位宽与数值
可以使用 nbits 属性获取 Bits 对象的位宽,uint() 方法获取无符号整数值,int() 方法获取有符号整数值。例如:
1 | a = Bits8(128) |
3.1.4 位切片与复制
- 位切片:Bits 对象可以像 Python 列表一样进行位切片以读取或写入特定位段。切片语法 [start:end] 包含 start 位、不包含 end 位。例如,
a[28:32]表示获取 a 的高四位。
示例:
1 | a = Bits32(0xabcd0123) |
在这段代码中,我们对一个 Bits32 对象进行了位切片:
a[28:32]:提取 a 的最高 4 位(第 28 位至第 31 位),返回一个 4 位的 Bits4 对象。
- 在 0xabcd0123 中,最高 4 位是 0xa(二进制为 1010)。
- 所以,a[28:32] 返回 Bits4(0xa)。
a[4:24]:提取 a 从第 4 位到第 23 位的位段,共 20 位,返回一个 Bits20 对象。
- 在 0xabcd0123 中,从第 4 位到第 23 位对应的二进制是 0b11001101000000010010,即 0xcd012。
- 因此,a[4:24] 返回 Bits20(0xcd012)。
请注意:由于N是2进制的位宽,因此位切片也是在2进制下进行的。例如:
1 | 位索引: 31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0 |
- 修改位段:通过赋值可以修改特定位段的值,例如,
a[28:32] = 0xf将高四位修改为f。 - 复制对象:直接赋值并不会复制 Bits 对象,而是创建引用。若想复制 Bits 对象,需要显式创建新对象。例如,
b = Bits32(a)会创建a的副本,之后对a或b的修改不会影响对方。例如:
1 | a = Bits32( 0xabcd0123 ) |
而
1 | a = Bits32( 0xabcd0123 ) |
3.2 Bits操作符(Bits Operators)
3.2.1 支持的操作符
PyMTL3 中的 Bits 对象支持多种操作符,分为以下几类:
- 逻辑操作符:包括按位与
&、按位或|、按位异或^和按位非~。 - 算术操作符:支持加法
+、减法-和乘法*。 - 缩减操作符:包括
reduce_and(按位与缩减)、reduce_or(按位或缩减)和reduce_xor(按位异或缩减),这些操作符会将 Bits 对象缩减为单个位宽。 - 移位操作符:支持右移
>>和左移<<。 - 关系操作符:包括相等
==、不等!=、大于>、大于或等于>=、小于<和小于或等于<=。
其他函数:
sext:符号扩展。zext:零扩展。concat:连接多个 Bits 对象。
注意:Python 还支持其他一些操作符(如除法 / 和取模 %),但在 PyMTL3 的 RTL 模型中这些操作符不可翻译,因此应避免使用。

3.2.2 操作符使用示例
逻辑与缩减操作符:可以对 Bits 对象执行逻辑运算。PyMTL3 支持自动将整数隐式转换为 Bits 对象,但如果两个 Bits 对象的位宽不同,会导致类型不匹配错误。可通过 sext 或 zext 扩展位宽,以匹配操作数的位宽。
1 | a = Bits4(0b1010) |
sext(符号扩展,symbol extend):符号扩展用于将带符号的数值扩展到更高的位宽。如果原始值是负数(即最高有效位为1),符号扩展会在扩展的高位填充1;如果是正数,则填充0。这种扩展方法适用于有符号数的操作。zext(零扩展,zero extend):零扩展用于将无符号数扩展到更高的位宽,扩展时在高位补零。适用于无符号数的操作。
例如:
1 | a = Bits4(0b1010) |
移位操作符:支持逻辑左移和右移。移位的位数可以是整数或 Bits 对象,右移时高位用零填充,移位结果的位宽与操作数的位宽一致。
1 | a = Bits4(0b1011) |
算术操作符:加法和减法操作的结果位宽为操作数位宽的最大值,支持模运算并采用二进制补码表示负数。
1 | a = Bits4(3) |
1 | a = Bits4(-2) |
关系操作符:支持比较两个 Bits 对象,结果为单个位宽的 Bits 对象,比较操作默认将操作数视为无符号整数。
1 | a = Bits4(3) |
其他函数:
- 连接:
concat可将多个 Bits 对象连接成一个新对象。
1 | a = Bits8(0xab) |
- 截断:
trunc可将 Bits 对象截断为较小的位宽(只取低N位)。
1 | a = Bits8(0xff) # 0b11111111 |
3.3 BitStruct 数据类型
BitStruct 是 PyMTL3 中用于定义带有命名位字段的结构体类型,这些字段具有固定的位宽。通过 BitStruct,可以将多种数据字段组合成一个紧凑的 Bits 对象,并为这些字段赋予便于访问和操作的名称。
3.3.1 创建 BitStruct
在 PyMTL3 中,使用 @bitstruct 装饰器定义 BitStruct 类,这类似于 Python 3.7 引入的 dataclass。以下是一个定义 Point 的示例,它表示一个二维点,包括 x 和 y 两个四位的字段:
1 |
|
创建 Point 实例时,可以直接赋值并访问各字段:
1 | pt1 = Point(3, 4) |
3.3.2 转换与打包
- 打包为 Bits 对象:使用
to_bits()方法可以将 BitStruct 实例打包为一个 Bits 对象,方便在更大的位结构中使用。此方法从最高有效位开始打包。
1 | pt1.to_bits() # 输出 Bits8(0x34),按高位优先顺序 |
- 解包为 BitStruct 实例:可以通过
from_bits方法将 Bits 对象解包为 BitStruct 实例:
1 | Point.from_bits(Bits8(0x34)) # 返回 Point(Bits4(0x3), Bits4(0x4)) |
3.3.3 参数化的 BitStruct
在某些情况下,字段的位宽可能在运行时才确定。PyMTL3 提供了 mk_bitstruct 函数,支持在运行时定义具有指定位宽的 BitStruct。例如,这是固定位宽的Point结构体:
1 | @bitstruct |
这是带参数化位宽的Point结构体。在运行时定义一个新的 PointN 结构体,使得 x 和 y 字段的位宽可以根据需要动态设置。这里使用 mk_bitstruct 函数,生成一个包含两个 nbits 位宽字段的 Point8 结构体:
1 | nbits = 8 |
第04章 寄存增量器(Registered Incrementer)
在本节中,我们将构建一个基本的 PyMTL3 硬件模型,学习如何模拟、可视化、验证、复用、参数化并封装此模型。我们将以一个8位加1器(Registered Incrementer)为例进行建模。好的设计实践是,在开始编码之前,先绘制硬件模型的图示,例如数据通路图、状态机图或控制信号表,这样可以确保模型准确反映设计意图。
请注意:使用两空格缩进,且仅使用空格避免混淆,而不是tab。
4.1 建模寄存增量器
我们设计一个8位加1器模型。该模型具有一个 8 位输入端口和一个 8 位输出端口。每个时钟上升沿,输入值会被寄存,并加 1 后输出。在下方拆解示例代码:
首先,从 PyMTL3 框架中导入所需内容,并定义 RegIncr 类继承自 Component 基类:
1 | from pymtl3 import * |
- Component 是 PyMTL3 模型的基类。
- 通过 construct 方法定义端口接口、内部信号和并发逻辑块。
声明输入和输出端口:
1 | s.in_ = InPort(Bits8) |
s.in_是 8 位输入端口(用 in_ 而不是 in,因为 in 是 Python 的保留字)。s.out是 8 位输出端口。- PyMTL3 模型中不需要显式定义时钟
clk和复位reset端口,它们是隐含的输入。
定义一个 8 位的内部信号 reg_out,用于存储寄存器的输出:
1 | s.reg_out = Wire(8) |
Wire 用于在并发块间传递数据,是一种内部信号。
使用 update_ff 装饰器定义寄存器逻辑,模拟寄存器的行为。update_ff 块在每个时钟上升沿调用一次,用于在寄存器中存储数据:
1 |
|
- 在 PyMTL3 中,
update_ff是一个特殊的装饰器,用来定义依赖时钟上升沿触发的逻辑块(我们称为“同步逻辑块”)。也就是说,update_ff块会在每个时钟上升沿被调用一次。 s.reset用于判断复位信号。如果复位,reg_out置为 0;否则,将输入端口的值赋给reg_out。- 使用
<<=操作符来实现非阻塞赋值,使得所有update_ff块在同一个时钟周期内看起来是并行执行的,这意味着即使我们在多个update_ff块中对信号进行赋值,这些赋值都会在当前时钟周期结束后才真正生效。
[为什么需要非阻塞赋值?]
在硬件电路中,多个寄存器和逻辑单元通常会在同一个时钟信号的控制下更新状态。如果使用阻塞赋值,当一个寄存器的值改变时,它会立即影响到依赖它的其他逻辑单元,从而导致电路在同一个时钟周期内产生不同步的更新,最终产生竞态条件或不稳定的行为。
非阻塞赋值的优点在于,它允许我们在时钟周期内并行更新多个寄存器的值,而不受彼此的影响。这样可以确保电路在每个时钟周期的边界上达到稳定状态,从而避免竞态和不稳定的情况。只需要参考该例:
1 |
|
然后,使用 update 装饰器定义递增逻辑,用于将 reg_out 的值加 1 并输出:
1 |
|
update表示组合逻辑块,响应信号的变化而立即更新。- 使用
@=操作符进行阻塞赋值,使更新立即生效。 - 每次
reg_out值变化时,block2将被触发,读取reg_out的值并加 1 后赋给s.out。
在 PyMTL3 中,复位信号(reset)只能在 update_ff 块中读取(同步复位),不能在 update 块中使用。如果需要在组合逻辑中利用复位信息,应通过复位信号初始化状态位,然后在组合逻辑中读取该状态位。
以下是完整的8位加1器的代码实现:
1 | from pymtl3 import * |
简单的工作流程如下:
- 寄存器更新:每个时钟上升沿,
block1被调用,将in_的值存储到reg_out。 - 递增逻辑:
reg_out值发生变化后,block2立即被调用,读取reg_out的值,加 1 后赋给out。 - 上述过程在每个时钟周期重复执行。
4.2 模拟模型
在创建了硬件模型后,我们可以通过编写一个模拟脚本来测试其功能。以下内容展示了如何使用一个简单的 Python 脚本来展开模型,创建模拟器,写入输入值并显示输入/输出端口的值。
首先,我们编写脚本 regincr-sim,它从命令行接收输入值,对 RegIncr 模型进行模拟,并输出各时钟周期的输入和输出值。
1 | #!/usr/bin/env python |
每个输入值经过以下几个步骤:
- 写入输入端口:使用
@=操作符将input_value写入模型的in_端口。这里@=的使用类似于update块中的信号写入,以确保值立即生效。 - 组合逻辑求值:调用
model.sim_eval_combinational()以评估组合逻辑,更新输出值。 - 输出显示:调用
print输出当前周期计数、输入值和输出值。 - 前进一个周期:调用
model.sim_tick(),模拟器进入下一个时钟周期。
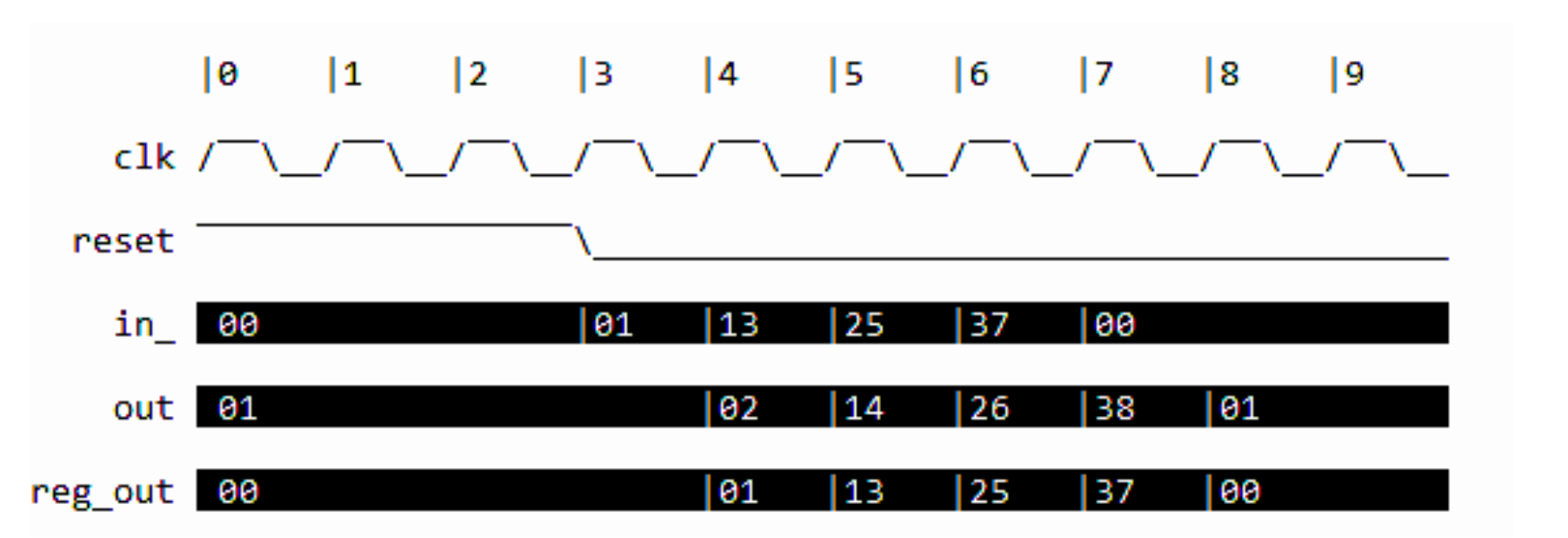
由于 sim_reset 方法将复位信号激活了两个周期,输出从第 3 周期开始显示。当新输入值写入递增器时,在下一个周期即可观察到对应的递增输出值。
以下是运行结果:
1 | # Line Tracing |
4.3 可视化
在设计的早期阶段,通过行跟踪 (line tracing) 可以调试设计的高级行为。然而,当我们需要查看更多信号的细节时,仅依靠行跟踪显得不够直观。PyMTL3 框架可以输出 VCD(Value Change Dump) 格式的波形文件,记录设计中每个信号(包括端口和内部信号)的变化,以便我们在工具中查看波形。
4.3.1 GTKwave
在 regincr-sim 脚本中,可以通过为 DefaultPassGroup 传递 vcdwave 参数来启用 VCD 输出。该参数指定生成的 VCD 文件的名称(无需添加 .vcd 后缀):
1 | model.apply(DefaultPassGroup(vcdwave='regincr-sim')) |
这行代码将配置 DefaultPassGroup 来生成名为 regincr-sim.vcd 的 VCD 文件。
在终端中执行以下命令以运行模拟脚本,并生成波形文件:
1 | cd ${TUTROOT}/tut3_pymtl/regincr |
这将根据输入数据运行模拟并生成 regincr-sim.vcd 文件。文件生成后,可以使用开源工具 GTKWave 来浏览波形:
1 | gtkwave regincr-sim.vcd & |
可以通过 GTKWave 的官方文档 了解更多实用功能。
这是输出的结果:

4.3.2 基于文本的波形
有时没有必要总是使用图形界面工具如 GTKWave 查看 VCD 文件查看,因为它涉及启动图形界面,尤其在远程服务器上可能会耗费较长时间。因此,在一些小规模设计或简单测试中,我们可以采用基于文本的波形查看方式。这种方式可以在终端内直接展示信号的变化,适用于少数周期的快速调试。
和前面相似,在 regincr-sim 脚本中,我们可以通过为 DefaultPassGroup 传递 textwave=True 参数来启用文本波形输出。还需要在模拟循环结束后调用 print_textwave 方法来打印波形。PyMTL3 设计上不会在模拟进行中自动输出文本波形,因此需要手动调用以便在模拟结束后统一输出:
1 | model.apply(DefaultPassGroup(textwave=True)) |
在结束循环后调用:
1 | model.print_textwave() |
这是输出结果:
1 | (pymtl3_env) (usr) albert@alberts-fedora:~/CSC/cpt4$ python regincr-sim.py 0x01 0x10 0x15 0x17 |
这是实际在终端中的输出结果示例:
4.4 使用pytest进行单元测试验证模型
4.4.1 pytest框架简介
在开发硬件模型后,验证其功能正确性是至关重要的环节。仅通过观察行跟踪(line trace)或波形文件来判断设计是否正确是一种“肉眼验证”的方式,容易出错且不具备可重复性。随着设计的复杂度增加,手动检查的方式变得不可行。因此,通过自动化单元测试,可以更严谨、系统化地验证模型的功能,并且在修改设计或进行团队协作时,也能更轻松地复现测试过程。
在本课程中,我们使用 pytest 框架进行单元测试,它提供了强大的功能,包括自动发现测试、参数化测试、丰富的报错信息、标准输出捕获等。pytest 使用非常简便,同时允许我们根据需求编写简单或复杂的测试。
pytest 框架拥有以下特点,非常适合硬件设计的测试:
- 自动:pytest 会自动寻找以
test_开头的函数,认为它们是测试用例。 - 标准断言语句:使用标准的
assert语句来检查预期值和实际值,无需额外学习专用的测试库函数。 - 命令行参数控制:支持参数化命令行控制,如生成 VCD 文件、设置输出捕获等。
- 报错:当断言失败时,pytest 会提供详细的上下文信息,包括变量值和函数调用栈,帮助快速定位问题。
以下代码展示了如何为 8 位加 1 器编写单元测试,并对模型的行为进行验证:
1 | from pymtl3 import * |
代码解析:
1 | model = RegIncr() |
使用 config_model_with_cmdline_opts 函数配置模型,cmdline_opts 收集命令行参数,如 --dump-vcd,用于控制是否生成 VCD 文件。
1 | model.apply(DefaultPassGroup(linetrace=True)) |
DefaultPassGroup 的 linetrace=True 选项启用了行跟踪输出,sim_reset 重置模拟器,使得模型处于初始状态。
然后,定义辅助函数 t:
1 | def t(in_, out): |
辅助函数 t 定义了一个单周期的测试,参数 in_ 表示输入值,out 表示期望输出值:
- 将
in_写入输入端口。 - 调用
sim_eval_combinational来评估组合逻辑,更新输出。 - 如果
out不等于?,表示需要验证输出值,通过assert语句进行检查。 - 使用
sim_tick模拟器前进一个时钟周期。
测试用例定义:
1 | t(0x00, '?') # 第一个周期,不关心输出值 |
每个周期的输入和期望输出在函数 t 中定义。通过这种逐周期的测试方法,可以精确地验证每个周期的输入输出关系。
这是实际输出结果示例(如果出现报错,可尝试降低pytest版本至7.2.0通过pip install pytest==7.2.0):
1 | (pymtl3_env) (usr) albert@alberts-fedora:~/CSC/cpt4$ pytest RegIncr_test.py |
4.4.2 运行测试脚本
将测试脚本 RegIncr_test.py 放置在目录中。pytest 会自动发现以 _test.py 结尾的文件并运行其中的测试用例。建议在单独的构建目录中运行测试,以避免生成文件混杂:
1 | mkdir ${TUTROOT}/build |
执行结果显示每个测试脚本和测试函数的通过情况,每个通过的测试用例会显示一个“.”,失败的测试用例会显示“F”。
4.4.3 使用pytest命令行选项
--capture=no 选项:默认情况下,pytest 会捕获标准输出。若希望在终端中查看行跟踪信息,可以通过 --capture=no 选项禁用输出捕获:
1 | pytest ../tut3_pymtl/regincr/test/RegIncr_test.py --capture=no |
--tb选项:当测试失败时,可以通过 --tb 参数调整错误输出的详细程度。--tb=short 会输出简短的错误信息,而 --tb=long 会输出完整的调用栈信息:
1 | pytest ../tut3_pymtl/regincr/test/RegIncr_test.py --tb=short |
--dump-vcd选项:如果需要生成 VCD 文件以便于在波形查看工具中进一步分析,可以在运行 pytest 时使用 --dump-vcd 选项。生成的 VCD 文件将包含测试的信号波形:
1 | pytest ../tut3_pymtl/regincr/test/RegIncr_test.py --dump-vcd |
4.5 使用测试向量验证模型
在硬件设计的单元测试中,通常需要多个定向测试用例来验证设计的不同方面。简单地重复写测试代码不仅冗长,还容易出错。为了简化测试代码,PyMTL3 提供了 run_test_vector_sim 辅助函数,允许通过测试向量(test vectors)的形式进行验证。这种方法将输入和期望输出以表格的方式展示,使得测试代码简洁清晰。
4.5.1 run_test_vector_sim 函数简介
run_test_vector_sim 是 PyMTL3 标准库中的一部分,用于简化基于测试向量的单元测试。这一函数的作用是:
- 自动展开模型并创建模拟器。
- 重置模拟器并写入测试向量表中的输入值。
- 读取模型输出并与测试向量表中的参考输出值进行比较。
测试向量表是一个二维列表,每一行表示一个时钟周期的输入输出关系:
- 第一行是表头,列出了端口名称。输出端口名以
*标识。 - 每一列对应一个输入或期望输出值。
- 每一行(从第二行开始)对应一个模拟周期的输入输出。
?表示我们不关心该周期的输出值。
以下示例展示了如何使用 run_test_vector_sim 对 8 位加 1 器模型进行三个测试:小输入值、大输入值以及溢出情况。
1 | from pymtl3 import * |
代码解析:
test_small函数:测试小输入值情况,输入从0x00, 0x03, 0x06, 0x00开始,期望输出为?, 0x01, 0x04, 0x07,以验证递增器的基本功能。test_large函数:测试大输入值情况,输入从0xa0, 0xb3, 0xc6, 0x00开始,期望输出为?, 0xa1, 0xb4, 0xc7,用于验证递增器对大输入值的处理。test_overflow函数:测试溢出情况,输入从0x00, 0xfe, 0xff, 0x00开始,期望输出为?, 0x01, 0xff, 0x00,用于检查递增器的溢出处理逻辑。
4.5.2 运行测试脚本
将测试脚本 RegIncr_extra_test.py 放置在目录中。可以在 build 目录下运行以下命令来执行测试脚本:
1 | cd ${TUTROOT}/build |
测试结果将显示每个测试函数的通过情况,成功的测试用例以 . 表示。此测试脚本可以自动发现并运行所有包含 _test.py 后缀的文件中的测试用例。这是输出结果:
1 | (pymtl3_env) (usr) albert@alberts-fedora:~/CSC/cpt4$ pytest RegIncr_extra_test.py |
4.5.3 使用 pytest 命令行选项
-v选项:用于显示详细输出,列出每个测试用例的执行结果。
1 | pytest ../tut3_pymtl/regincr/test -v |
-k选项:可以用于选择运行特定名称的测试用例。例如,运行名称包含 small 的测试用例。
1 | pytest ../tut3_pymtl/regincr/test -k small |
-x选项:在遇到第一个失败的测试用例时停止运行。
1 | pytest ../tut3_pymtl/regincr/test -x |
4.5.4 三步调试法
当测试一个目录中的所有测试用例时,可以采用三步调试法逐步缩小问题范围:
- 运行所有测试:获取当前目录下所有测试用例的总体执行情况,了解哪些测试通过,哪些失败。
1 | pytest ../tut3_pymtl/regincr/test/ |
- 查看详细输出:使用
-v选项运行单个测试脚本,观察失败的具体测试用例。
1 | pytest ../tut3_pymtl/regincr/test/RegIncr2stage_test.py -v |
- 逐步调试:结合
-x、-k、--tb=short等选项,进一步缩小调试范围,定位问题。
1 | pytest ../tut3_pymtl/regincr/test/RegIncr2stage_test.py -v -x --tb=short |
4.6 使用随机测试验证模型
在前面的测试中,我们采用了定向逐周期灰盒测试策略,手动设计了特定的输入输出来验证模型的功能。然而,除了手工编写的定向测试外,随机测试也能有效提高验证的覆盖率和测试的严谨性。通过随机生成输入值,能帮助发现手动测试难以察觉的潜在错误。
Python 提供的 random 模块可以方便地生成随机输入值,但在使用随机测试时需要注意模型的延迟,确保每个期望的输出值出现在正确的周期位置上。以下是一个适用于8位加1器模型的随机测试用例示例。
以下代码展示了如何生成随机测试向量表,并利用 run_test_vector_sim 函数来进行随机测试:
1 | import random |
代码解析:
- 导入 random 模块:使用 Python 的 random 模块生成随机输入值。
- 定义测试向量表:
1 | test_vector_table = [('in_', 'out*')] |
初始化测试向量表,首行为表头,in_ 为输入端口,out* 为输出端口。
- 设置期望输出的初始值:
1 | last_result = '?' |
last_result 初始值为 '?',表示在第一个周期不关心输出值。
- 生成随机测试向量:
1 | for i in range(20): |
- 循环生成 20 个测试向量,每次随机生成一个 8 位输入值
rand_value。 rand_value和last_result被添加到测试向量表中。- 更新
last_result为当前输入值加 1 的结果,用于下一个周期的期望输出。trunc_int=True确保溢出时截断到 8 位。
- 运行测试:
1 | run_test_vector_sim(RegIncr(), test_vector_table, cmdline_opts) |
通过 run_test_vector_sim 函数运行测试向量模拟,以验证模型对随机输入的处理是否正确。
我们还可以运行随机测试并启用行跟踪。在终端中执行以下命令运行随机测试用例,并启用行跟踪(-s 选项显示输出):
1 | cd ${TUTROOT}/build |
此命令将运行 test_random 测试函数,并打印出行跟踪信息,有助于观察每个周期的输入输出关系。-k random 参数确保仅运行包含random名称的测试。
注意:在设计随机测试时,应考虑模型的延迟,确保期望输出与正确的周期对应。对于复杂模型,可以增加随机测试的周期数以增强测试覆盖率。
4.7 两级寄存递增器的设计与测试
本节详细介绍了如何通过模块化和层次化设计思想,将简单的单级寄存递增器模型(RegIncr)组合成一个两级寄存递增器(RegIncr2stage)。
下图展示了两级寄存递增器的硬件结构,其中:
- 输入端口 in 接收 8 位数据。
- 两个 RegIncr 模块串联,分别完成递增操作。
- 输出端口 out 传递最终结果。

以下为两级寄存递增器的 PyMTL3 实现。
1 | from pymtl3 import * |
代码解析
接口定义:
s.in_是输入端口,接收 8 位宽的数据。s.out是输出端口,输出最终的处理结果。
模块实例化:
- 分别实例化了两个单级寄存递增器(
RegIncr),分别完成第一阶段和第二阶段的递增操作。
端口连接:
- 使用 connect 方法和
//=操作符连接输入、输出和子模块接口。
层次化设计:
- line_trace 方法结合子模块的 line_trace 输出,提供了两阶段递增器内部状态的完整视图。
测试脚本通过多个测试用例验证了两级寄存递增器的功能,包括:
- 小值测试(Small Test):测试小范围数据的递增功能。
- 大值测试(Large Test):验证较大范围数据的处理情况。
- 溢出测试(Overflow Test):测试数据溢出的正确性。
- 随机测试(Random Test):随机生成数据进行验证,覆盖更广的数据范围。
以下为部分测试脚本实现:
1 | import random |
逻辑说明:
延迟处理:
- 由于两级寄存递增器的两周期延迟,前两周期的输出为未知值(
?)。 - 测试用例在第三周期开始断言输出值是否正确。
随机测试:
- 随机生成 20 组输入数据,通过计算参考输出(
+2),验证递增器的功能正确性。 - 延迟处理同样适用于随机测试,注意保持参考输出与实际行为的一致性。
输出结果为:
1 | (pymtl3_env) (usr) albert@alberts-fedora:~/CSC/cpt4$ pytest RegIncr2stage_test.py |
接下来可以进行运行测试与结果分析。
1 | # 运行所有测试用例 |
运行以下命令生成线性跟踪信息:
1 | % pytest ../tut3_pymtl/regincr/test/RegIncr2stage_test.py -k test_small -s |
图 20 展示了 test_small 测试的线性跟踪结果,其中:
- 每一列对应模型中不同模块的状态。
- 数据从
in输入,经过reg_incr_0和reg_incr_1两阶段处理,最终输出到out。 - 通过观察高亮标注的
0x03,可以清晰地看到数据如何逐周期传递并递增。

运行的输出结果为:
1 | (pymtl3_env) (usr) albert@alberts-fedora:~/CSC/cpt4$ pytest RegIncr2stage_test.py -k test_small -s |
使用以下命令生成 VCD 波形文件:
1 | % pytest ../tut3_pymtl/regincr/test/RegIncr2stage_test.py --dump-vcd |
以下是生成的vcd波形文件,分别为small与random:


4.8 使用“静态”展开进行组件参数化
在硬件设计中,参数化组件能够显著提高模块的复用性,并支持灵活的设计空间探索。PyMTL3 提供了动态硬件生成工具,结合 Python 的动态特性,允许通过参数化实现组件的“静态”展开。参数化组件可以通过构造函数传递参数来决定组件的接口、行为以及子组件的结构组合。
需要注意的是:
- PyMTL3 的静态展开(Static Elaboration)发生在模拟器或测试脚本的运行时,通过 Python 的动态代码生成硬件结构。
- 这种展开过程与传统硬件描述语言(如 Verilog 或 VHDL)的静态展开类似,只不过 PyMTL3 是在“运行时”完成展开。
- 参数化组件的不同配置需要独立验证,这通常要求更加复杂的测试策略以覆盖所有可能的参数组合。
下面是一个支持位宽(nbits)和递增量(amount)参数化的组合逻辑递增器。
1 | class Incrementer( Component ): |
- 端口宽度通过
nbits参数控制,适用于不同数据宽度的输入和输出信号。 - 递增量由
amount参数决定,使递增器能够适配不同加法需求。
下面是一个支持寄存器级数参数化的多级寄存递增器(RegIncrNstage)。通过参数 nstages,用户可以灵活指定寄存递增器的级数。
1 | from pymtl3 import * |
参数化组件的不同配置需要动态生成测试用例和测试向量,以覆盖所有参数组合。
对于参数化的寄存递增器,其参考输出与级数(nstages)相关,需要动态生成测试向量表。
1 | def mk_test_vector_table( nstages, inputs ): |
解析:
- 延迟模拟:
- 使用
collections.deque模拟多级寄存递增器的延迟。 - 输入向量后补零,确保输出参考值正确。
- 位截断:
- 使用
trunc_int=True确保计算结果符合位宽限制。
通过 pytest.mark.parametrize,可以为参数化组件生成测试用例。
1 | test_case_table = mk_test_case_table([ |
- 每一行对应一个参数化测试,列表示不同的参数。
pytest.mark.parametrize自动生成并运行对应的测试用例。
使用随机生成的输入向量对多级寄存递增器进行测试。
1 |
|
- 使用
sample(range(0xff), 20)生成 20 个随机输入值。
运行所有测试用例:
1 | % cd ${TUTROOT}/build |
运行指定测试用例:
1 | % pytest ../tut3_pymtl/regincr/test/RegIncrNstage_test.py -k 3stage -sv |
生成波形文件:
1 | % pytest ../tut3_pymtl/regincr/test/RegIncrNstage_test.py --dump-vcd |
- 测试通过显示
PASSED,若失败会显示FAILED。 - 参数化测试生成的测试用例以方括号标记参数组合(如
test[2stage_small])。
4.9 打包模型集合
在硬件设计中,尤其是使用 PyMTL3 框架时,将相关模型组织到单独的子目录中可以显著提升项目的模块化程度。通过打包(Packaging),可以使这些子目录成为标准的 Python 包,并通过 import 命令方便地在其他子项目中复用这些模型。本节详细介绍了如何配置打包、使用模型集合,以及如何正确管理包路径。
- 什么是打包?
- 打包是将一个子目录(即子项目)转换为标准 Python 包的过程。一个打包的子项目可以通过
import命令访问其内部的模型、函数或类。 - 打包的核心是创建一个 Python 包配置脚本,命名为
__init__.py,并将其放置在子项目的根目录中。
- 子项目目录结构
- 子项目通常由一组相关模型组成,位于一个单独的子目录中。
- 如果子项目中存在嵌套的子目录,每个子目录都需要包含一个
__init__.py文件,即使该文件为空。
__init__.py的作用
__init__.py脚本的主要功能是导入子项目中的模型、函数或类,从而创建包命名空间。
下面展示了 regincr 包的配置脚本 __init__.py 的内容。
1 | #========================================================================= |
解析:
- 导入模型:
- 将
regincr子项目中的所有模型导入包命名空间。 - 使用
from .表示从当前目录(即regincr子目录)导入模块。
- 灵活扩展:
- 除了模型,还可以将其他功能,例如辅助函数或工具类,导入包命名空间,供外部使用。
在项目根目录(TUTROOT)中,可以直接导入打包后的 regincr 子项目,并对其中的模型进行使用和仿真。
下面展示了如何从项目根目录导入包,并对模型进行简单仿真。
1 | % cd ${TUTROOT} # 切换到项目根目录 |
我们之前建议使用conda在虚拟环境中运行,如果你遵守了,操作流程也是类似的。
在 Python 交互环境中,运行以下命令:
1 | >>> from pymtl3 import * # 导入 PyMTL3 框架 |
解析:
使用
from tut3_pymtl.regincr import RegIncr导入模型。使用 PyMTL3 的 API 对模型进行仿真,包括初始化、设置输入值、执行时钟周期操作,以及读取输出值。
四、从构建目录中导入包
如果切换到构建目录(build),直接导入 tut3_pymtl.regincr 包会报错。因为 Python 默认的搜索路径不包含 tut3_pymtl 包所在的项目根目录。
下面展示了如何通过设置环境变量 PYTHONPATH 解决这一问题。
1 | % cd ${TUTROOT}/build # 切换到构建目录 |
在 Python 交互环境中,运行以下命令:
1 | >>> from tut3_pymtl.regincr import RegIncr # 导入 RegIncr 模型 |
使用
env PYTHONPATH=".."将项目根目录添加到 Python 包搜索路径。调用
model.elaborate()方法展开模型,生成完整的硬件结构。使用 PyMTL3 提供的接口检查方法,例如
get_input_value_ports()和get_wires(),可以获取模型的输入输出端口及内部连线信息。
PyMTL3 框架提供了一系列强大的 API,用于检查已展开(elaborated)模型的结构和组件。这些工具对于调试复杂模型和参数化模型尤为有用。
- 获取端口信息:
get_input_value_ports():返回模型的输入端口列表。get_output_value_ports():返回模型的输出端口列表。
- 获取内部连线:
get_wires():返回模型内部的连线。
- 获取子组件:
get_child_components():返回模型的子组件列表。
- 获取并发块:
get_update_blocks():返回模型的并发块。
示例:
1 | >>> model.get_input_value_ports() # 检查输入端口 |
第05章 排序单元(Sort Unit)
5.1 排序单元的 FL 模型
功能级(Functional-Level,FL)模型专注于实现目标硬件的功能行为,而不关注具体的硬件时序。FL 模型通常是硬件设计的第一步,它可以快速实现功能验证,同时为后续的周期级(Cycle-Level,CL)和寄存器传输级(Register-Transfer-Level,RTL)模型设计打下基础。
排序单元(Sort Unit)的功能是对四个输入值进行排序,使输出端口按从小到大的顺序排列。排序单元具有以下接口:
输入端口:
in_val:标志输入值是否有效。in_[0:3]:四个待排序的输入值。
输出端口:
out_val:标志输出值是否有效。out[0:3]:按升序排列的输出值。
下图使用 “cloud diagram” 对排序单元进行了抽象表示,重点突出其功能逻辑,而忽略了具体的实现细节:

FL 模型的设计主要关注以下几点:
- 功能实现:使用简单的排序函数实现输入值的排序逻辑。
- 有效性标志:通过
in_val和out_val标志输入和输出值的有效性。 - 行跟踪(Line Trace):提供易于阅读的输入输出状态显示。
- 默认信号重置:依赖 PyMTL3 框架的默认信号初始化功能。
以下代码展示了排序单元 FL 模型的实现,核心功能是对输入端口的四个值进行排序,并通过输出端口返回结果。
1 | from pymtl3 import * |
代码解释:
- 排序功能实现(
sort_fl函数):
- 使用 Python 的内置
sorted函数对数组进行排序。 - 该函数对
in_输入端口的四个值排序后,将结果传递给输出端口out。
- 输入输出端口定义:
InPort和OutPort用于定义输入和输出接口,支持参数化位宽(默认为 8 位)。- 输入端口包括
in_val(输入有效性标志)和in_[0:3](四个待排序的值)。 - 输出端口包括
out_val(输出有效性标志)和out[0:3](排序后的值)。
- 核心排序逻辑:
- 使用
@update_ff定义逻辑块,确保信号值在时钟上升沿后更新。 - 通过非阻塞赋值(
<<=)将排序后的结果赋值到输出端口。 - 输入有效性标志
in_val被直接传递到输出有效性标志out_val。
- 行跟踪(Line Trace):
- 提供
line_trace方法,用于在模拟过程中格式化显示输入输出状态。 - 当输入或输出无效时,用空格代替显示,使得行跟踪信息更加直观。
- 例如:{8,3,5,1}|{1,3,5,8} 表示输入值为 {8,3,5,1},排序后输出 {1,3,5,8}。
- 默认信号重置:
- PyMTL3 框架默认将信号初始化为 0,简化了 FL 模型的设计。
- 这种简化在 CL 模型中也适用,但在 RTL 模型中需要显式实现状态重置。
接下来可以进行排序单元的测试。排序单元测试包括四个定向测试用例和一个随机测试用例。这些测试验证了 SortUnitFL 的功能正确性:
1 | from pymtl3 import * |
- 运行所有测试:
1 | >>> cd ${TUTROOT}/build |
- 运行基本测试:
1 | >>> pytest ../tut3_pymtl/sort/SortUnitFL_test.py -k test_basic -s |
- 运行随机测试:
1 | >>> pytest ../tut3_pymtl/sort/SortUnitFL_test.py -k test_random -s |
如前面所述,FL模型有如下几个最直接的作用:
- 早期验证:FL 模型可以快速实现并验证硬件设计的基本功能,为后续的 CL 和 RTL 模型提供测试基准。
- 模块化设计:通过 FL 模型验证功能后,可在更高抽象级别逐步优化和细化设计。
- 代码复用性:在 FL 模型中完成的测试用例可以直接复用于 CL 和 RTL 模型,确保验证过程一致。
这是实际的输出结果:
1 | (pymtl3_env) (usr) albert@alberts-fedora:~/CSC/cpt5$ pytest SortUnitFL_test.py -v -s |
5.2 排序单元的 CL 模型
在 FL(功能级)模型的基础上,我们可以逐步将其细化为 CL(周期级)模型。CL 模型捕获硬件目标的周期近似行为,关注其在每个时钟周期内的性能表现,而不是单纯的功能正确性。
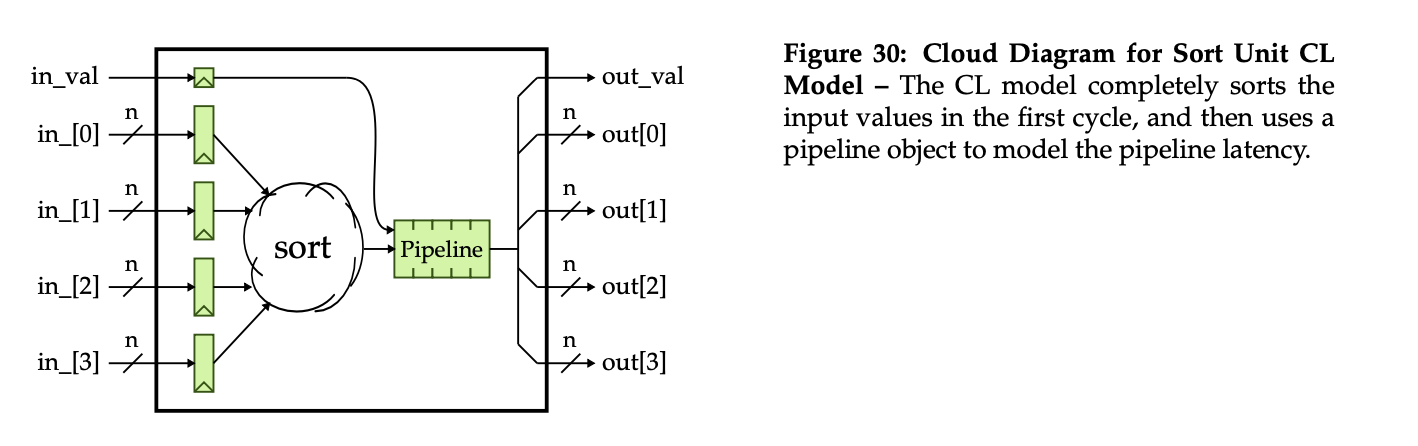
CL 模型在第一周期完成输入值的排序,并使用流水线模拟目标硬件的周期延迟。如 Figure 30 所示:
- 输入端口 in_ 和 in_val 提供值及其有效性标志。
- 排序逻辑在第一周期内完成值的排序。
- 使用 pipe(双端队列)模拟流水线延迟,将排序结果在多个周期内逐步输出。
- 输出端口 out_ 和 out_val 提供按顺序排列的结果及其有效性。
以下代码展示了排序单元 CL 模型的具体实现,重点在于使用流水线结构模拟硬件的延迟:
1 | from collections import deque |
代码解释:
- 双端队列
pipe的作用
双端队列(deque)是 Python 标准库 collections 模块中的一种数据结构,用于高效地在序列两端添加或删除元素。
- 模拟流水线延迟:
在硬件中,流水线的延迟表现为信号从输入端逐步传播到输出端的过程。在这个 CL 模型中,pipe作为一个双端队列,用于存储每个时钟周期的输入有效信号in_val和排序后的数据列表sort_fl(s.in_)。 - 元素格式:
队列的每个元素是一个列表,包含有效性标志in_val和排序结果[sorted_value1, sorted_value2, sorted_value3, sorted_value4]。例如:
1 | [1, 2, 3, 4, 5] # 1 是有效信号,2–5 是排序后的值 |
- 模拟延迟逻辑
在每个时钟周期:
- 调用
append方法将新的输入有效信号和排序后的数据加入队列末尾。 - 调用
popleft方法从队列头部取出最早的信号值和数据,用于更新输出端口。 - 初始化长度:
队列的初始长度为nstages - 1(流水线的阶段数减一)。例如,当nstages=3时,初始队列长度为 2。这种设计在nstages=1时(单周期延迟)能够直接运行,不会增加额外的延迟。
- 深拷贝
deepcopy
Python 的赋值操作默认是引用传递,这意味着多个变量可能同时指向同一个对象。如果直接将输入信号和排序后的结果添加到队列中,可能会出现以下问题:
- 信号值在后续周期被修改时,队列中存储的值也会随之改变。
- 导致信号不稳定或与预期不符。
解决方案:
- 使用
copy模块中的deepcopy函数对信号和排序结果进行深度拷贝,生成一个独立的副本。 - 深拷贝确保了队列中的值与输入信号完全独立,避免了因共享内存而引发的副作用。例如:
1 | s.pipe.append(deepcopy([s.in_val] + sort_fl(s.in_))) |
- 更新块逻辑
更新块是通过 @update_ff 装饰器定义的同步逻辑,它在每个时钟上升沿被调用,模拟硬件中寄存器的行为。
排序与存储:
- 调用
sort_fl(s.in_)函数对输入信号列表s.in_进行排序。 - 使用深拷贝将输入有效信号
s.in_val和排序后的列表组合后追加到队列末尾。
队列的读取:
- 调用
popleft从队列头部取出最早的信号值和数据。 - 将有效性标志
data[0]赋值给输出端口s.out_val,并将排序后的数据列表赋值给输出数据端口s.out[i]。
流水线延迟:
- 队列的长度为
nstages - 1,每次调用append和popleft操作都会导致数据沿着流水线推进一段距离。 - 如果
nstages=3,则总延迟为 3 个周期(包括更新块本身的 1 个周期延迟)。
- 行跟踪(Line Trace)
行跟踪用于在测试和调试过程中直观地展示输入和输出信号的变化。
- 显示输入状态:
- 将输入端口
s.in_的值通过map和str转换为字符串,并用花括号包裹。 - 当
in_val无效时,用空格替代对应的字符串,以清晰显示无效周期。例如:
1 | in_str = '{' + ','.join(map(str, s.in_)) + '}' |
显示输出状态:
- 将输出端口
s.out的值转换为字符串,同样在无效周期中用空格替代。 - 输出字符串与输入字符串通过
|分隔,表示输入输出之间的关系。 - 输出格式:
行跟踪的结果是一个固定宽度的字符串,便于观察信号的传递。例如:
1 | {04,02,03,01}| # 第 4 周期:输入有效,输出无效 |
代码逻辑图解
- 初始化队列:
- 假设
nstages=3,则队列初始状态为:
1 | [[0, 0, 0, 0, 0], [0, 0, 0, 0, 0]] # 两个占位元素 |
- 周期操作:
- 周期 1:输入
{4, 2, 3, 1},排序后追加队列:
1 | [[0, 0, 0, 0, 0], [1, 1, 2, 3, 4]] |
周期 2:从队列头部取出一个值更新输出,同时追加新输入。
周期 3:队列状态为:
1 | [[1, 1, 2, 3, 4]] |
输出 {1, 2, 3, 4}。
CL 模型的测试使用参数化测试,包括定向测试和随机测试,覆盖了不同输入值和不同流水线深度。
测试示例代码
1 | from pymtl3 import * |
- 运行所有测试:
1 | >>> cd ${TUTROOT}/build |
- 运行特定测试:
1 | >>> pytest ../tut3_pymtl/sort/test/SortUnitCL_test.py -k 3stage_stream -s |
Figure 32 显示了测试的行跟踪输出:
- 第 3 周期:无输入和输出。
- 第 4 周期:输入值
{4, 2, 3, 1}被记录。 - 第 7 周期:输出值
{1, 2, 3, 4}被排序后输出。

这是实际输出结果:
1 | (pymtl3_env) (usr) albert@alberts-fedora:~/CSC/cpt5$ pytest SortUnitCL_test.py -v -s |
此结果验证了 CL 模型正确捕获了排序单元的周期行为。
5.3 排序单元的 RTL 模型
在完成了对功能级(FL)和周期级(CL)模型的探索后,我们将设计进一步深化为RTL模型(寄存器传输级模型)。RTL模型具备以下特性:
- 周期准确性:严格模拟硬件的周期行为。
- 资源准确性:具体实现硬件所需的资源,包括寄存器、比较器等。
- 位级准确性:每一位的操作符合硬件逻辑。
在本节中,我们实现了一个三级流水线的排序单元,采用了Bitonic排序网络进行四个输入值的排序。以下为模型设计的详细说明。
如图(Figure 33)所示,RTL模型使用三级流水线,每一级实现部分排序,逐步将输入数据排序为输出数据。其中,每个流水线阶段包含:
- 数据的输入寄存器化。
- min/max单元:对两个输入进行比较,较小值输出至上方端口,较大值输出至下方端口。

排序网络是三级流水线实现的Bitonic网络:
- 第一阶段(S1):分别比较元素对
(0,1)和(2,3)。 - 第二阶段(S2):分别比较元素对
(0,2)和(1,3)。 - 第三阶段(S3):比较元素对
(1,2)。
最终结果在第七个时钟周期输出,保证了模型的流水线周期级行为。
设计原则:
- 输入寄存器化(Registered Inputs):每个流水线阶段的输入均通过寄存器进行存储,以避免关键路径延迟。
- 清晰的阶段划分:每一级流水线的逻辑清晰分离,使用寄存器存储每一级的结果。
- 复位信号显式处理:RTL模型中所有状态均需显式复位,确保在硬件初始化时的正确性。
以下为排序单元RTL模型的部分代码实现,展示了接口定义、输入寄存器化及第一阶段(S1)的组合逻辑:
1 | from pymtl3 import * |
代码解释:
- 接口定义
s.in_val和s.out_val是布尔型信号,分别表示输入有效性和输出有效性。s.in_和s.out是四个输入和输出数据端口,位宽可通过参数 nbits 定义。
- 输入寄存器化
- 使用
update_ff模拟寄存器行为。 - 每个时钟周期,将输入有效性信号
s.in_val和输入数据s.in_存储到寄存器中。 - 在复位信号激活时,将所有寄存器清零。
- 第一阶段组合逻辑
- 通过
update定义组合逻辑。 - 比较输入数据对
(0,1)和(2,3),将较小值存储到上方端口,较大值存储到下方端口。 - 输出结果存储在
s.elm_next_S1中,供下一阶段使用。
测试脚本包含以下内容:
- 四个定向测试(directed tests)。
- 一个随机测试(random test)。
这是参考的测试脚本:
1 | from pymtl3 import * |
运行测试命令如下:
1 | % cd ${TUTROOT}/build |
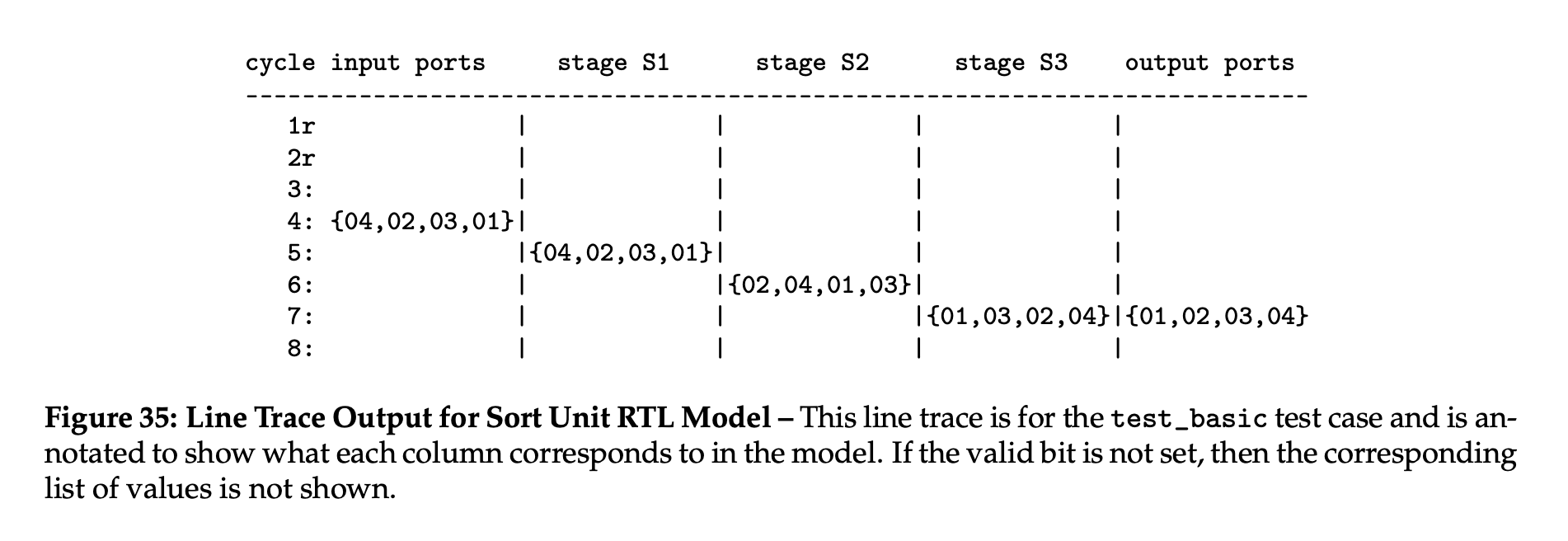
输出行跟踪如下(Figure 35):
这是实际的输出:
1 | (pymtl3_env) (usr) albert@alberts-fedora:~/CSC/cpt5$ pytest SortUnitFlatRTL_test.py -v -s |
5.4 基于结构化 RTL 模型的排序单元
平面RTL模型虽然可以直接实现排序单元,但其设计复杂且代码单一,难以有效利用排序器内部的层次化结构。在这一节中,我们采用结构化RTL模型,通过模块化和层次化的设计方法,将复杂设计分解为多个子模块。这种方法的主要优点包括:
- 可维护性:通过模块化分离复杂功能,降低了设计和测试的复杂性。
- 独立测试:每个子模块可以独立开发和测试,从而提高整体模型的可靠性。
- 代码清晰性:层次化的设计使得代码更易读且逻辑清晰。
它的设计思想如下:
- 结构化设计:
- 使用寄存器存储流水线中每个阶段的中间状态。
- 将排序逻辑封装到独立的最小-最大单元(MinMaxUnit)中。
- 模块化流水线:
- 每个流水线阶段由寄存器和组合逻辑组成。
- 数据从一个阶段流入下一个阶段,同时每个阶段执行特定的排序逻辑。
- 测试可复用性:
- 测试脚本可共享之前的测试向量和测试工具,提高测试效率。
以下是排序单元结构化RTL模型的代码(以第一个流水线阶段为例):
1 | from pymtl3 import * |
代码详解:
- 接口定义:
- 定义了一个输入有效信号端口
in_val和一个输出有效信号端口out_val,用于指示输入数据和输出数据的有效性。 - 定义了4个输入端口
in_和4个输出端口out,每个端口的位宽为nbits(默认为8位)。
- 流水线寄存器(Stage S0->S1):
- 使用RegRst寄存器存储输入有效信号(
in_val),并支持复位功能。 - 使用4个普通寄存器(
Reg)存储输入数据,每个寄存器分别对应4个输入端口。 - 通过//=操作符连接寄存器的输入和接口的输入,实现信号的直连。
- 组合逻辑(
Stage S1):
- 实例化两个最小-最大比较单元(MinMaxUnit),每个单元比较两个输入数据并输出较小值和较大值。
- 第一组比较单元(
minmax0_S1)比较寄存器elm_S0S1[0]和elm_S0S1[1]的输出数据。 - 第二组比较单元(
minmax1_S1)比较寄存器elm_S0S1[2]和elm_S0S1[3]的输出数据。
- 模块间连接:
- 使用
//=操作符将寄存器输出连接到比较单元输入,避免声明中间信号,简化代码。
测试脚本:
结构化RTL模型的测试脚本包含以下几个关键点:
- 测试脚本复用:
- 使用SortUnitCL_test.py中的
mk_test_vector_table生成测试向量,从而复用已有的测试逻辑。
- 测试用例:
- 包含四个定向测试(directed tests)和一个随机测试(random test),覆盖了排序单元的主要功能。
- 运行测试:
- 执行所有测试:
1 | cd ${TUTROOT}/build |
- 查看基本测试的行跟踪:
1 | pytest ../tut3_pymtl/sort/test/SortUnitStructRTL_test.py -k test_basic -s |
5.5 使用模拟器评估排序单元
在硬件设计中,评估(Evaluation)是验证(Verification)之后的关键一步。评估的核心目标是量化设计性能,例如执行某个输入数据集所需的时钟周期数、平均延迟、吞吐量等。这一步的重点在于使用模拟器而不是单元测试,模拟器通过完整的循环流程运行设计,生成统计数据,而不再关注具体功能是否正确。
模拟器的功能
- 处理命令行参数:通过参数指定实现模型、输入模式等选项。
- 生成输入数据集:支持多种输入模式(如随机输入、升序输入、降序输入)。
- 实例化并展开设计:根据指定的实现类型创建模型。
- 主循环运行设计:驱动输入信号,检测输出有效信号,记录设计行为。
- 生成性能统计数据:包括总时钟周期数、平均每次排序所需周期数等。
以下是简化版模拟器脚本的代码和功能详细说明:
1 | opts = parse_cmdline() # 解析命令行参数 |
代码详解
- 生成输入数据集
- 根据
--input命令行参数生成输入数据: - 随机模式(random):每组数据包含4个随机数,范围为[0, 255]。
- 升序模式(sorted-fwd):生成升序排列的输入数据。
- 降序模式(sorted-rev):生成降序排列的输入数据。
- 可以通过修改
ninputs变量调整数据集大小。
- 实例化并展开模型
- 使用字典
model_impl_dict映射命令行参数到模型类,实现灵活切换模型: cl模型:周期近似模型,快速模拟排序行为。rtl-flat模型:平面RTL模型,直接实现硬件行为。rtl-struct模型:结构化RTL模型,通过层次化结构实现更高的代码复用性。
配置选项包括:
- 是否生成波形文件(
--dump-vcd)。 - 是否进行Verilog测试(
--test-verilog)。
- 执行主循环
- 模拟器通过主循环驱动设计,记录输出有效信号并计算性能统计数据。
输入处理逻辑:
- 如果输入队列非空,则弹出一组数据,驱动输入端口。
- 如果输入队列为空,则设置输入信号为无效。
输出处理逻辑:
- 检测
out_val信号,统计输出次数。
调用流程:
sim_eval_combinational():更新组合逻辑。sim_tick():前进一个时钟周期。
- 统计结果输出
- 模拟器通过
--stats选项输出以下统计信息: - 总时钟周期数(
num_cycles):完成所有数据处理所需的总周期数。 - 平均每次排序的周期数(
num_cycles_per_sort):衡量设计的吞吐量。
命令行参数使用示例
- 评估不同实现模型
1 | cd ${TUTROOT}/build |
- 使用不同的输入数据集
1 | ../tut3_pymtl/sort/sort-sim --stats --impl cl --input random # 随机输入 |
- 生成行跟踪和波形文件
1 | ../tut3_pymtl/sort/sort-sim --stats --impl rtl-struct --trace --dump-vcd |
注意事项
- 模拟器与单元测试的区别:
- 模拟器:关注设计的性能指标,例如吞吐量和延迟。
- 单元测试:验证设计的功能正确性。
- 流水线启动开销:
- 模拟结果显示,每次排序的平均时钟周期略高于1,这是由于流水线启动阶段的开销。
- 设计验证与性能评估的分离:
- 模拟器假定设计功能正确,所有功能验证工作应在测试阶段完成。
5.6 将排序单元的 RTL 模型翻译为 Verilog
完成从功能级(FL)模型到周期级(CL)模型,再到寄存器传输级(RTL)模型的逐步细化设计后,我们需要将RTL模型翻译为硬件描述语言(HDL),如Verilog或SystemVerilog。
PyMTL3框架提供了强大的翻译功能,支持从RTL模型到Verilog的转换,同时保持模型的层次性和可读性。
翻译流程
- 基本翻译实现
翻译流程通过VerilogTranslationPass实现,以下是关键步骤:
1 | # 导入相关模块 |
运行上述代码后,PyMTL3将生成翻译后的Verilog代码。
- 输出文件
文件命名:SortUnitFlatRTL__nbits_8__pickled.v。
- 文件名包含模型的参数信息(如
nbits=8),确保不同参数化实例的模块名唯一。
文件内容:
- 翻译生成的Verilog代码保留了模块层次。
update_ff块翻译为always_ff块。update块翻译为always_comb块。- 每个并发块的PyMTL3代码会以注释形式保留在Verilog代码中,方便调试。
- 代码特点
- 层次保留:翻译工具保留了模型的模块层次结构,如子模块实例化。
- 易读性:通过名称修饰规则(name mangling),生成的Verilog代码具有良好的可读性。
翻译优化:
- 翻译结果支持缓存机制,避免重复翻译相同模型。
- 在调试过程中可通过注释和层次结构快速定位问题。
高级翻译功能
PyMTL3提供了VerilogTranslationImportPass,其功能远超简单的Verilog代码生成。它可以
1. 翻译RTL模型为Verilog。
2. 使用Verilator工具将Verilog代码转换为C++。
3. 生成C++包装器,用于调用Verilog的C++仿真。
4. 创建PyMTL3包装器,将C++包装器嵌入PyMTL3模型,形成一个精确的周期级硬件模拟器。
这一流程允许在PyMTL3中无缝调用翻译后的Verilog,同时使用相同的测试脚本验证模型功能。
翻译后可以进行模型测试。以下是一个支持翻译后模型测试的单元测试脚本示例:
1 | from pymtl3 import * |
以下是运行测试的命令:
1 | # 测试PyMTL3 RTL模型 |
测试过程中会生成多个波形文件(VCD文件),包括:
- sort-pymtl.vcd:用于测试原始PyMTL3 RTL模型。
- 测试翻译后的Verilog模型的波形文件(两个VCD文件分别对应PyMTL3包装器和实际Verilog设计)。
最终,我们可以使用模拟器脚本生成排序单元的Verilog代码和波形文件,这些文件可用于FPGA或ASIC工具链。
1 | ../tut3_pymtl/sort/sort-sim --impl rtl-flat --input random --translate --dump-vcd |
- Title: PyMTL基础入门
- Author: Albert Cheung
- Created at : 2024-11-07 20:20:39
- Updated at : 2024-11-25 17:42:36
- Link: https://www.albertc9.github.io/2024/11/07/introduction-to-pymtl-basics/
- License: This work is licensed under CC BY-NC-SA 4.0.
