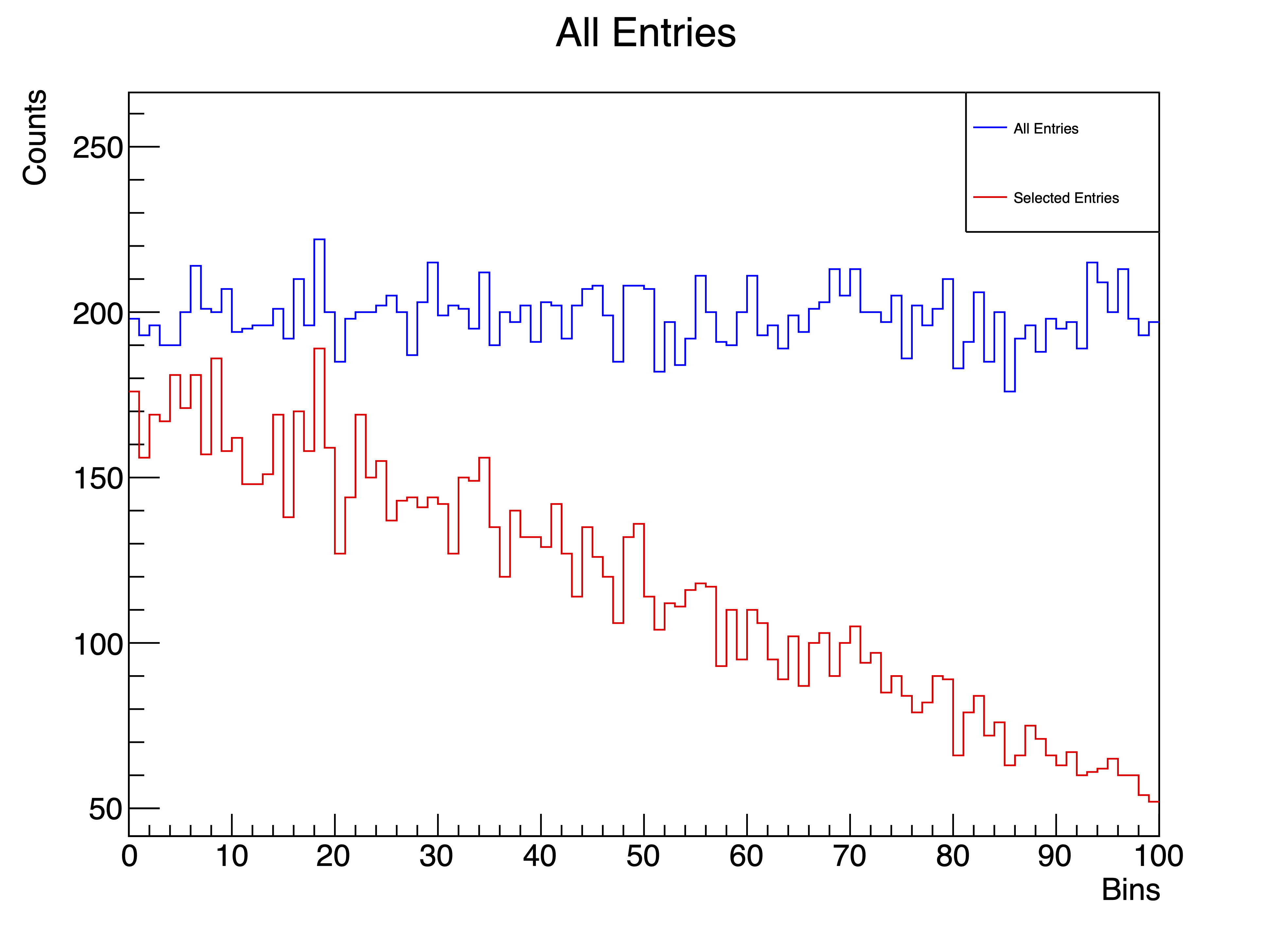
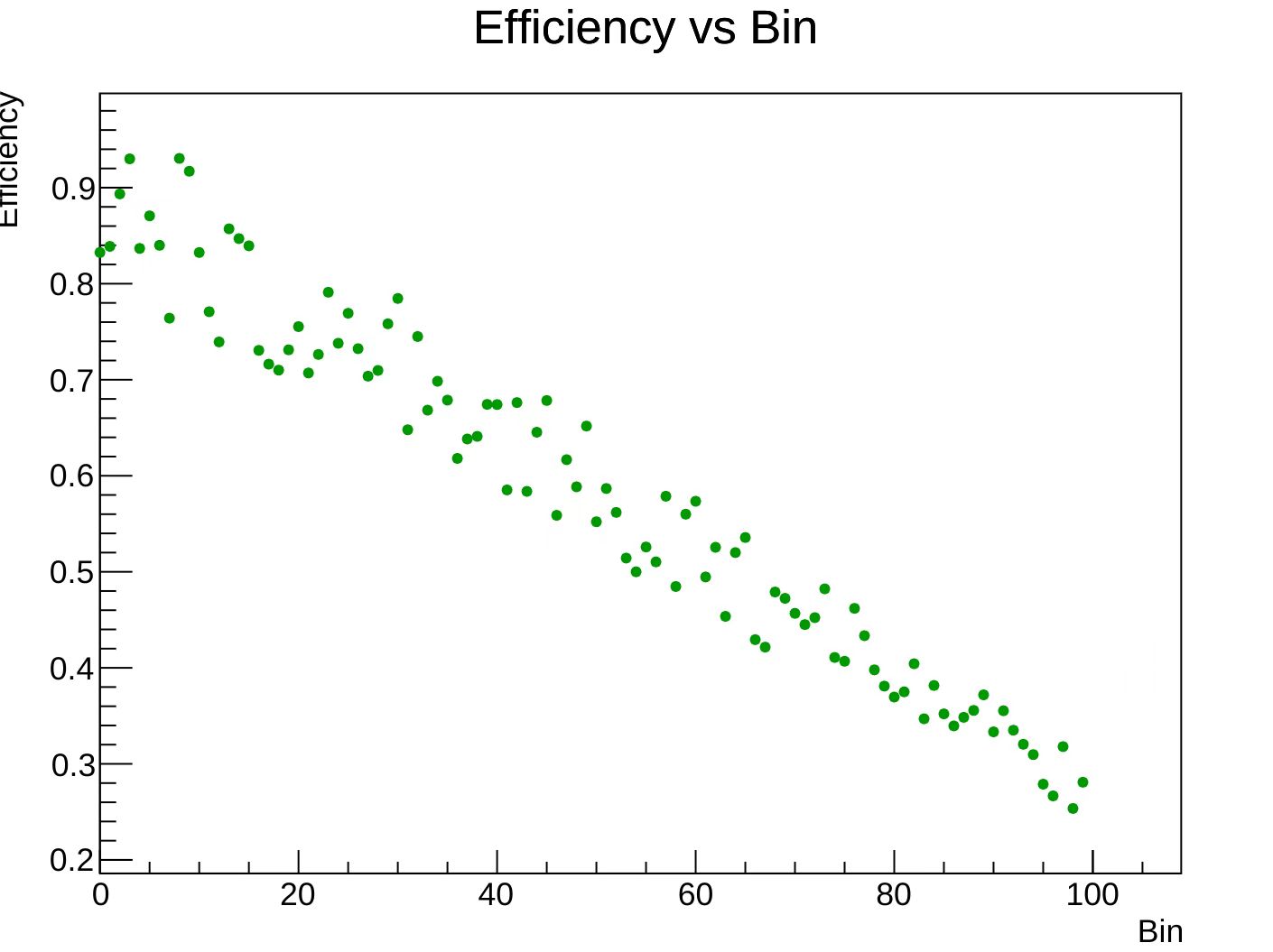
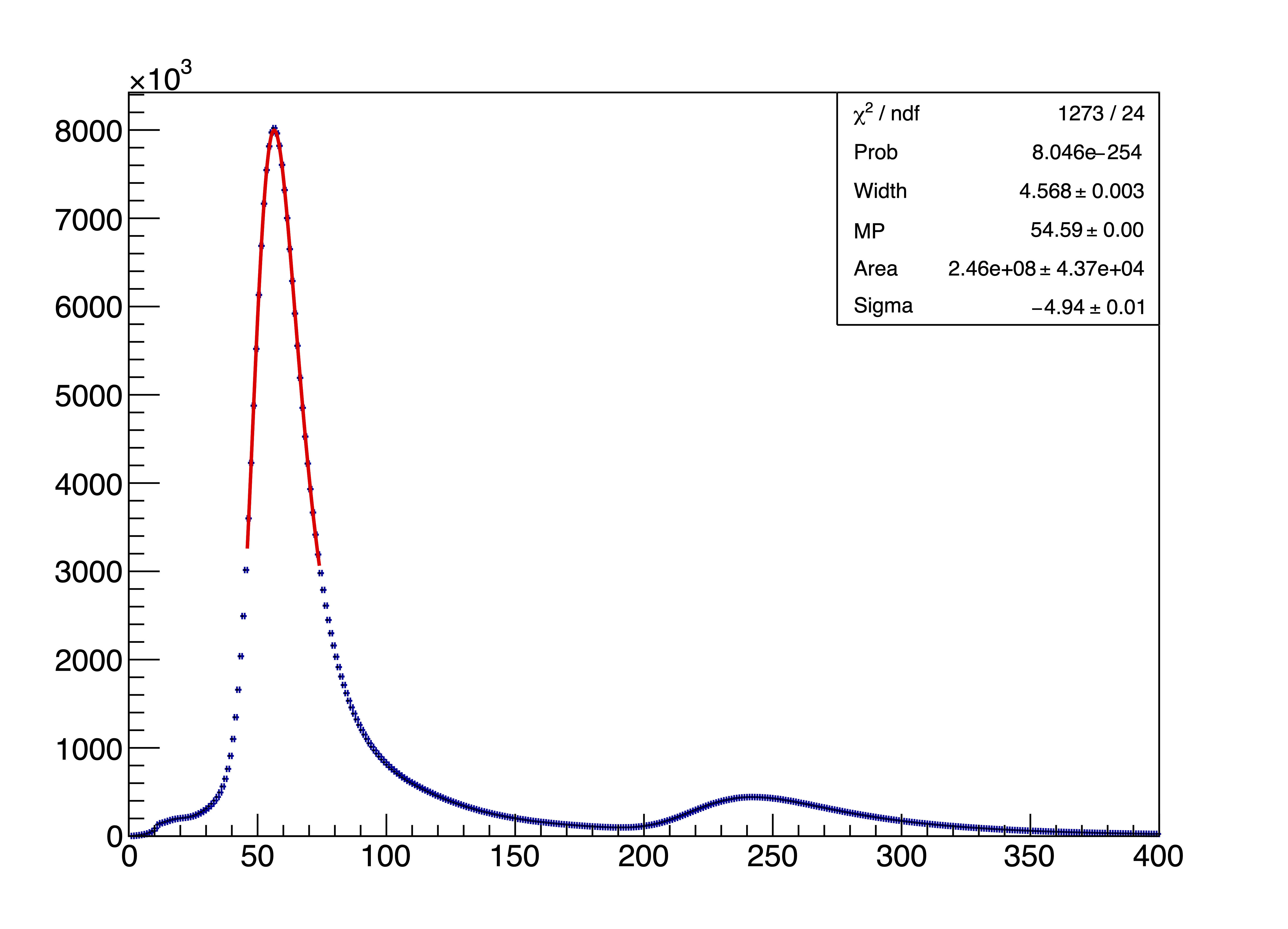
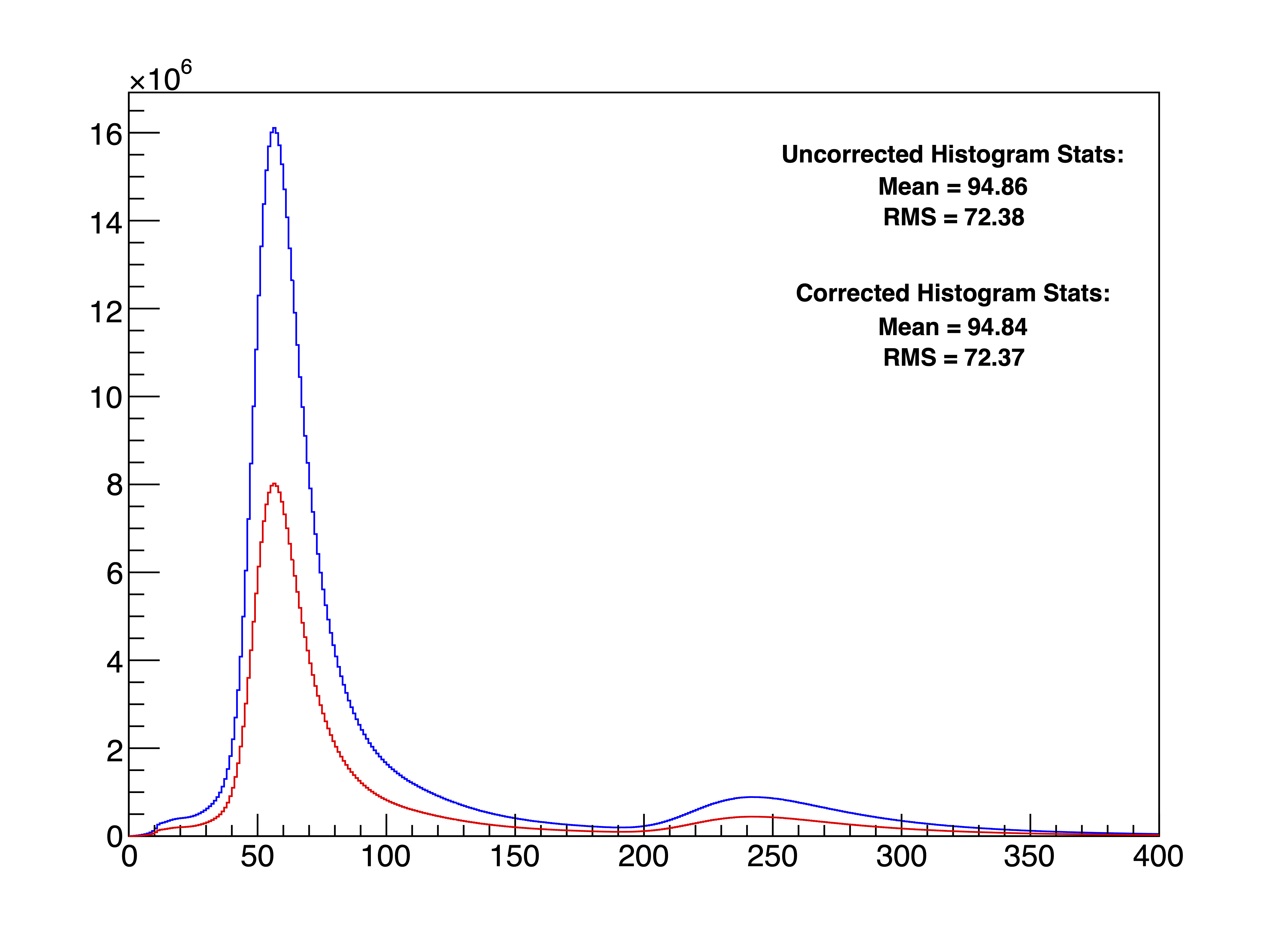
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
| /*
* 注意1:在ROOT中,直方图默认与当前目录关联(例如TFile)。当关闭TFile时,与其关联的所有直方图都会被删除,如果之后需要调用的话就会产生无效的内存访问。这可能是我在运行中偶尔出现 crash 的原因。
* 注意2:在所有部分,我只计算了区间(45,80)的卡方/自由度。
*/
void atask1_6() {
auto start = std::chrono::high_resolution_clock::now(); // 记录程序运行时间
TVirtualFitter::SetDefaultFitter("Minuit"); // **在上一次程序运行中发现无法使用 Minuit 改用 Minuit2,这一次发现无法使用 Minuit2 改用 Minuit。由于每个A_B都要提示一次(1152次),于是预先在这里声明。但是为什么?**
TFile *file = TFile:: Open("va.root", "READ");
TFile *outFile = new TFile("fit_results.root","RECREATE");
std::ofstream outputFile("chi2Ndf_and_gainCoefficients.txt");
TH2D *gainMap = new TH2D("gainMap", "GainCoefficients; A; B", 192, 0, 192, 6, 0, 6);
TH2D *chi2Map = new TH2D("chi2Map", "ChiSquared/NDF; A; B", 192, 0, 192, 6, 0, 6);
double totalMPV = 0; // 用于累加MPV
int numDetectors = 0; // 探测器数量
std::vector<double> mpvList; // 每个探测器的MPV
std::vector<TH1D*> correctedHists; // 输出的(校正后的)值方图
std::vector<TH1D*> originalHists; // 由于出现了程序崩溃,存储一个原始直方图。应该是程序开头的注释中提到的问题
int lefFit = 0, riFit = 0, lefMergedFit = 0, riMergedFit = 0; // 拟合区间
lefFit = 45;
riFit = 75;
lefMergedFit = 45;
riMergedFit = 75;
for (int A=0; A < 192; ++A){
for (int B=0; B < 6; ++B){
TString histName = TString::Format("%d_%d", A, B);
TH1D *hist = (TH1D*)file -> Get(histName);
TH1D *histClone = (TH1D*)hist -> Clone();
histClone -> SetDirectory(0); // 克隆后解除关联(也是为了防止读取空内存)
histClone -> Sumw2(); // 计算误差,方便后续误差条的显示(虽然并不明显?)
originalHists.push_back(histClone);
// originalHists.push_back((TH1D*)hist -> Clone()); // 再次存储一个直方图
TF1 *landauGausFit = new TF1("landauGausFit", langaufun, lefFit, riFit, 4); // 选择区间的原因在文章中有说明
landauGausFit -> SetParameters(1.8, 50, 50000, 3);
landauGausFit -> SetRange(lefFit, riFit);
landauGausFit -> SetParNames("Width", "MP", "Area", "Sigma");
landauGausFit -> SetNpx(1000); // 由于初步拟合时发现峰值附近的拟合函数看起来太尖锐,手动增加绘制精度
hist -> Fit(landauGausFit, "Q", "", lefFit, riFit);
double gainCoefficient = landauGausFit -> GetMaximumX(lefFit, riFit);
double chi2 = 0;
int ndf = 0;
for (int bin = hist -> FindBin(45); bin <= hist -> FindBin(90); bin ++){
double observed = hist -> GetBinContent(bin);
double expected = landauGausFit -> Eval(hist -> GetBinCenter(bin));
if (expected > 0){
chi2 += (observed - expected) * (observed - expected) / expected;
ndf++;
}
}
ndf -= 4;
double chi2NDF = chi2 / ndf;
gainMap -> SetBinContent(A + 1, B + 1, gainCoefficient);
chi2Map -> SetBinContent(A + 1, B + 1, chi2NDF);
outputFile << A << "_" << B << " " << chi2NDF << " " << gainCoefficient << "\n";
mpvList.push_back(gainCoefficient);
totalMPV += gainCoefficient;
numDetectors ++;
hist -> Write();
}
}
double targetMPV = totalMPV / numDetectors; // 计算平均值用来对齐
for (int A = 0; A < 192; ++A){
for (int B = 0; B < 6; ++B){
TH1D *hist = originalHists[A * 6 + B];
double gainCoefficient = mpvList[A * 6 + B];
double correctionFactor = targetMPV / gainCoefficient; // 定义一个修正(对齐)因子
TH1D * correctedHist = (TH1D*)hist -> Clone(TString::Format("corrected_%d_%d", A, B));
correctedHist -> SetDirectory(0); // 也是解除关联
correctedHist -> Sumw2();
correctedHist -> Scale(correctionFactor);
correctedHists.push_back(correctedHist);
correctedHist -> Write();
}
}
// 这是未对齐的直方图
TH1D *mergedHistUncorrected = nullptr; // 初始化为空
for (int A = 0; A < 192; ++A) {
for (int B = 0; B < 6; ++B) {
TString histName = TString::Format("%d_%d", A, B);
TH1D *histFromFile = (TH1D*)file->Get(histName); // 直接从文件获取直方图
if (A == 0 && B == 0) { // 初始创建 mergedHistUncorrected
mergedHistUncorrected = (TH1D*)histFromFile->Clone("merged_hist_uncorrected");
mergedHistUncorrected->Reset();
mergedHistUncorrected->SetDirectory(0); // 解除关联
mergedHistUncorrected->Sumw2();
}
mergedHistUncorrected->Add(histFromFile); // 合并数据
}
}
// 这是一个用于合并的直方图
TH1D *mergedHist = (TH1D*)correctedHists[0] -> Clone("merged_hist");
mergedHist -> Reset();
mergedHist -> SetDirectory(0); // 也是解除关联
mergedHist -> Sumw2(); // 计算误差
for (size_t i = 0; i < correctedHists.size(); ++i){
mergedHist -> Add(correctedHists[i]);
mergedHistUncorrected -> Add(originalHists[i]);
}
double bestChi2NDF = 1e6;
int bestLefFit = 40, bestRiFit = 75;
for (double lower = 40; lower <= 48; lower += 0.5) {
for (double upper = 60; upper <= 75; upper += 0.5) {
TF1 *tempFit = new TF1("tempFit", langaufun, lower, upper, 4);
tempFit -> SetParameters(1.8, 50, 50000, 3);
tempFit -> SetRange(lower, upper);
tempFit -> SetParNames("Width", "MP", "Area", "Sigma");
tempFit -> SetNpx(1000);
mergedHist->Fit(tempFit, "Q", "", lower, upper);
double tempChi2 = 0;
int tempNDF = 0;
for (int bin = mergedHist->FindBin(45); bin <= mergedHist->FindBin(80); bin++) {
double observed = mergedHist->GetBinContent(bin);
double expected = tempFit->Eval(mergedHist->GetBinCenter(bin));
if (expected > 0) {
tempChi2 += (observed - expected) * (observed - expected) / expected;
tempNDF++;
}
}
tempNDF -= 4;
double tempChi2NDF = tempChi2 / tempNDF;
// 判断是否为最优
if (tempChi2NDF < bestChi2NDF) {
bestChi2NDF = tempChi2NDF;
bestLefFit = lower;
bestRiFit = upper;
}
delete tempFit;
}
}
TF1 *mergedFit = new TF1("mergedFit", langaufun, bestLefFit, bestRiFit, 4);
mergedFit -> SetParameters(1.8, 50, 50000, 3);
mergedFit -> SetRange(bestLefFit, bestRiFit);
mergedFit -> SetParNames("Width", "MP", "Area", "Sigma");
mergedFit -> SetNpx(1000);
mergedHist -> Fit(mergedFit, "Q", "", bestLefFit, bestRiFit);
double mergedChi2 = 0;
int mergedNDF = 0;
for (int bin = mergedHist -> FindBin(45); bin <= mergedHist -> FindBin(80);bin ++){
double observed = mergedHist -> GetBinContent(bin);
double expected = mergedFit -> Eval(mergedHist -> GetBinCenter(bin));
if (expected > 0){
mergedChi2 += (observed - expected) * (observed - expected) / expected;
mergedNDF++;
}
}
mergedNDF -= 4;
double mergedChi2NDF = mergedChi2 / mergedNDF;
mergedFit -> Write();
mergedHist -> Write();
mergedHistUncorrected -> Write();
gainMap -> Write();
chi2Map -> Write();
file -> Close();
outFile -> Close();
outputFile.close();
delete file;
delete outFile;
TFile *inFile = TFile::Open("fit_results.root", "READ");
TH2D *gainHist = (TH2D*)inFile -> Get("gainMap"); // 增益系数热力图
TH2D *chi2Hist = (TH2D*)inFile -> Get("chi2Map"); // 卡方分布热力图
TH1D *mergedHistUncorrectedFromFile = (TH1D*)inFile -> Get("merged_hist_uncorrected");
TH1D *mergedHistFromFile = (TH1D*)inFile -> Get("merged_hist"); // 合并后的直方图
TF1 *mergedFitFromFile = (TF1*)inFile -> Get("mergedFit"); // 拟合后的合并后的直方图
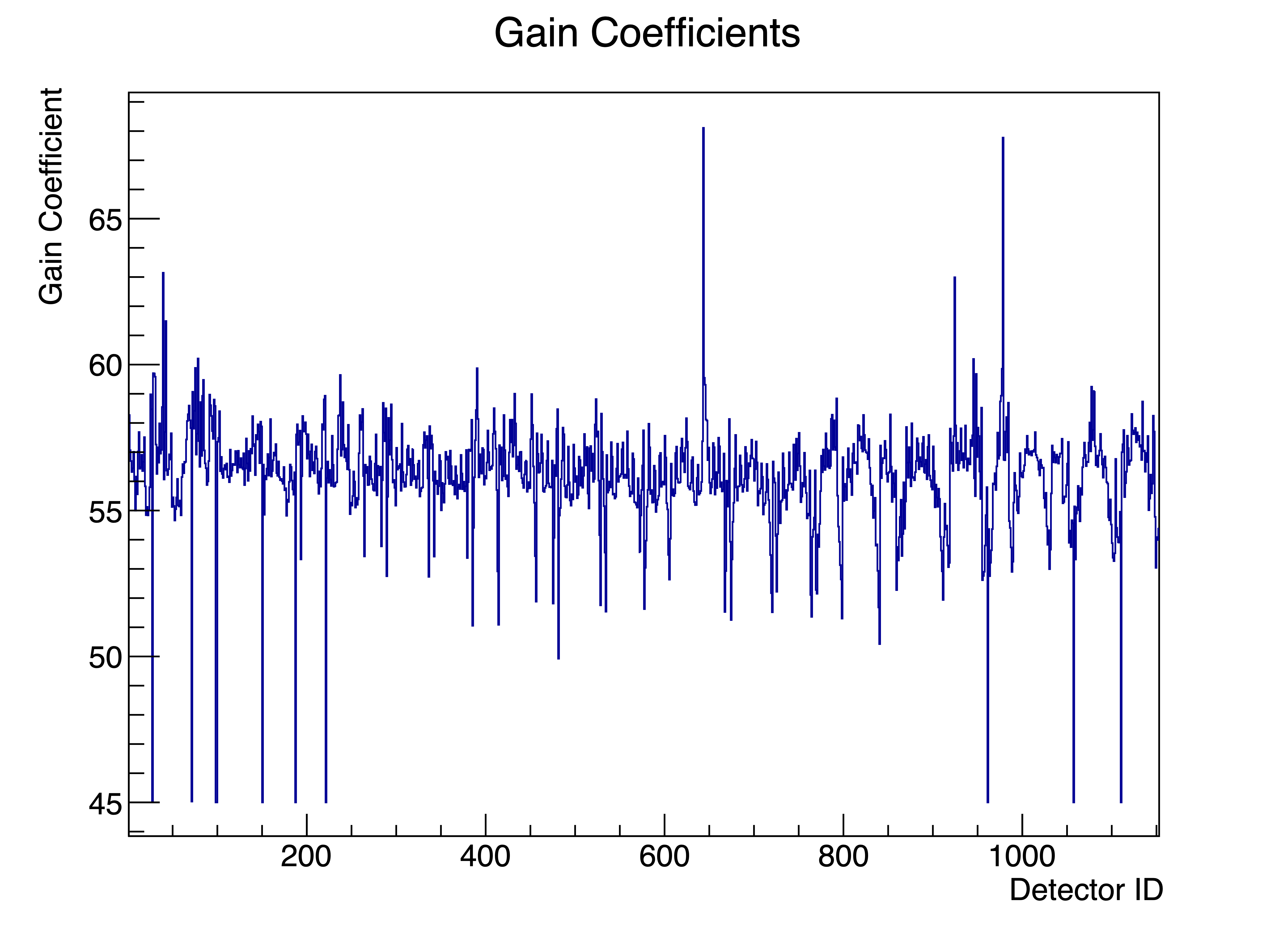
TH1D *gainHist1D = new TH1D("gainHist1D", "Gain Coefficients; Detector ID; Gain Coefficient", 1152, 1, 1153); // 1152 bin的直方图,用于绘制增益系数
TCanvas *c1 = new TCanvas("c1", "Gain Coefficient Heatmap", 800, 600);
gStyle -> SetOptStat(0);
gainHist -> Draw("COLZ");
c1 -> SaveAs("gain_heatmap.pdf");
TCanvas *c2 = new TCanvas("c2", "ChiSquared/NDF Heatmap", 800, 600);
gStyle -> SetOptStat(0);
chi2Hist -> Draw("COLZ");
c2 -> SaveAs("chi2Ndf_heatmap.pdf");
TCanvas *c3 = new TCanvas("c3", "Merged Spectrum Comparison", 800, 600);
mergedHistUncorrectedFromFile->SetLineColor(kBlue);
mergedHistFromFile->SetLineColor(kRed);
mergedHistUncorrectedFromFile->Draw("HIST");
double meanUncorrected = mergedHistUncorrectedFromFile->GetMean();
double rmsUncorrected = mergedHistUncorrectedFromFile->GetRMS();
TPaveText *statsUncorrected = new TPaveText(0.6, 0.75, 0.88, 0.85, "NDC");
statsUncorrected->SetFillColor(0);
statsUncorrected->AddText("Uncorrected Histogram Stats:");
statsUncorrected->AddText(TString::Format("Mean = %.2f", meanUncorrected));
statsUncorrected->AddText(TString::Format("RMS = %.2f", rmsUncorrected));
statsUncorrected->Draw("SAME");
mergedHistFromFile->Draw("SAME HIST");
double meanCorrected = mergedHistFromFile->GetMean();
double rmsCorrected = mergedHistFromFile->GetRMS();
TPaveText *statsCorrected = new TPaveText(0.6, 0.6, 0.88, 0.7, "NDC");
statsCorrected->SetFillColor(0);
statsCorrected->AddText("Corrected Histogram Stats:");
statsCorrected->AddText(TString::Format("Mean = %.2f", meanCorrected));
statsCorrected->AddText(TString::Format("RMS = %.2f", rmsCorrected));
statsCorrected->Draw("SAME");
// 这里的 merged_spectrum 实际上是对每个原始直方图进行郎道卷积高斯函数拟合,得到MPV,计算平均MPV后以 correctionFactor = targetMPV / gainCoefficient 作为校正因子对齐得到的合并的直方图
c3 -> SaveAs("merged_spectrum_comparison.pdf");
TCanvas *c4 = new TCanvas("c4", "Fitted Merged Spectrum", 800, 600);
gStyle -> SetOptFit(1111);
mergedHistFromFile -> Draw("E1Y0");
mergedFitFromFile -> SetLineColor(kRed);
mergedFitFromFile -> Draw("SAME");
gPad -> Update();
TPaveStats *stats = (TPaveStats*)mergedHistFromFile -> FindObject("stats");
if (stats){
stats -> SetX1NDC(0.65);
stats -> SetY1NDC(0.65);
stats -> SetX2NDC(0.90);
stats -> SetY2NDC(0.90);
stats -> SetBorderSize(1);
stats -> AddText(TString::Format("Chi2/NDF = %.2f", mergedChi2NDF));
}
c4 -> SaveAs("fitted_merged_spectrum.pdf");
TCanvas *c5 = new TCanvas("c5", "Gain Coefficients 2D plot", 800, 600);
for (int i = 0; i < 1152; ++i){
gainHist1D -> SetBinContent(i+1, mpvList[i]);
}
gainHist1D -> Draw("HIST");
c5 -> SaveAs("gain_coefficients_1D_plot.pdf");
inFile -> Close(0);
c1 -> Close(0);
c2 -> Close(0);
c3 -> Close(0);
c4 -> Close(0);
c5 -> Close(0);
auto end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double> elapsed = end - start;
std::cout << "Optimal fit range: [" << bestLefFit << ", " << bestRiFit << "], with Chi2/NDF:" << mergedChi2NDF << "." << std::endl;
std::cout << "Attention: All Chi2 / NDF are in the range of [45, 80]." << std::endl;
std::cout << "Total execution time: " << elapsed.count() << " seconds." << std::endl;
}
|